Build a Movie Recommender System in Python
 |
| Movie Recommendation System |
What is Recommendation System?
As it clear by name Recommender System is a system that seeks to predict or filter preferences according to the user's choices. A recommendation system takes the information about the user as an input.
Recommender systems are utilized in a variety of areas including movies, music, news, books, research articles, search queries, social tags, and products in general.
Recommender system is the most basic application of machine learning. Some real life examples of recommender system:
 |
| Google as recommendation engine. |
- Google gives us suggestions when we type something in the search box based on our search history.
 |
| Recommendation at Netflix Scale |
- Netflix's machine learning based recommendations learn from their own users.The recommendation system works putting together data collected from different places. Every time you press play and spend some time watching a TV show or a movie, Netflix is collecting data that informs the algorithm and refreshes it. The more you watch the more up to date the algorithm is.
 |
| Amazon Recommendations work |
- Amazon currently uses item-to-item collaborative filtering, which scales to massive data sets and produces high-quality recommendations in real time. This type of filtering matches each of the user's purchased and rated items to similar items, then combines those similar items into a recommendation list for the user.
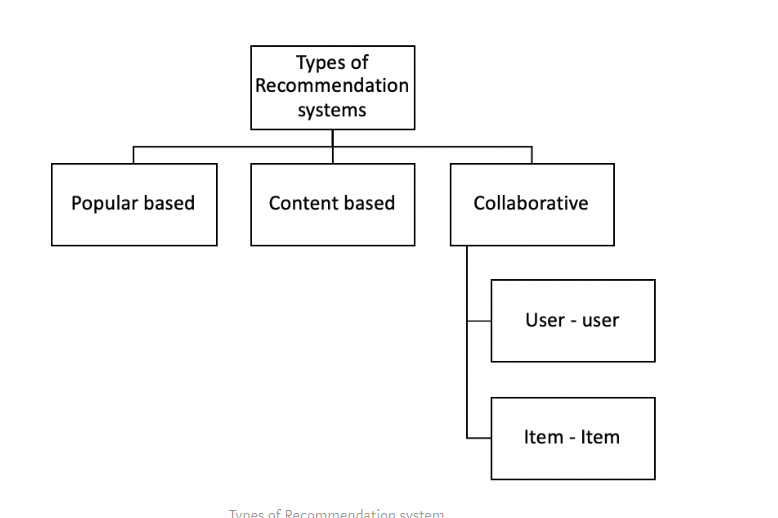
Types of Recommender System::
There are basically two main components of any recommendation system, Users and Items.
Let’s understand by taking some examples:
Netflix recommends movies to the people, hence movies are items and people are users, while Facebook recommends the people you may know to the people, here people are users and people are items too.
 |
| Types of Recommendation System |
There are three types of recommend system that are mostly used::
Popularity Based Recommender System::
As the name suggests the Popularity based recommendation system works with the trend. It basically uses the items which are in trend right now.
For Example:YouTube trending list recommends the most popular video of the day.

Collaborative Based Recommender System::
Collaborative Filtering based recommender system creates profiles of users based on the items the user likes. Then it recommends the items liked by a user to the user with similar profile.
There are two types of collaborative Based recommender system::
- User-Based
- Item-Based
 |
| Collaborative Based Recommender System |
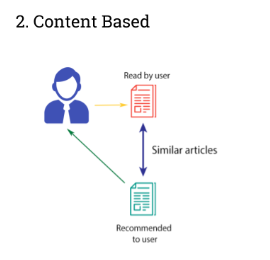
Content Based Recommender System::
Content based recommender systems recommends similar items used by the user in the past.
For Example:: Netflix recommends us the similar movies to the movie we recently watched.
 |
| Content Based Recommender System |
Content Based Recommender System Working::
Now we will look How does it decide which item is most similar to the item user likes.
Here we use similarity Score.
What is similarity Score?
It is a numerical value ranges between zero to one which helps to determine how much two items are similar to each other on a scale of zero to one. This similarity score is obtained measuring the similarity between the text details of both of the items. So, similarity score is the measure of similarity between given text details of two items.
Here we’ll use cosine similarity between text details of items. In the example below it is shown how to get cosine similarity:
Example::
text 1 ="Pakistan all Pakistan"
text 2 ="All Pakistan All
Step:1
Count the number of unique words in both texts.
There are only two unique words between both texts."Money" and "All".
Step 2:
Count the frequency of each word in each text.
 |
| Frequency Table |
Step 3 :
There are only two unique words, hence we’re making a 2D graph.
Now we need to find the cosine of angle ‘a’, which is the value of angle between both vectors. Here is the formula used for doing this:

Python | Measure similarity between two sentences using cosine similarity::


Now let’s see how to make a Content Based Recommender System in Python.
Building It In Python::
So we are going to make Hollywood Movie Recommender System::
Here we are using the IMDB-5000 Movie Dataset from Kaggle.
kaggle dataset link:
https://www.kaggle.com/carolzhangdc/imdb-5000-movie-dataset
After downloading the data, unzip it and there will be two .csv files. Check them out. We’ll use ‘movie_metadata.csv’ in our code.
Now we be will it in making JUPYTER NOTEBOOK.
LET'S START:
- Import NumPy and Pandas.

- Read the .csv file with pandas.

- Take a look at the dataset.

- Dealing with the null values. Filling them with string ‘unknown’.

- Replace NAN values.

● In the ‘genres’ column, replacing the ‘|’ with whitespace, so the genres would be considered different strings.

- Now converting the ‘movie_title’ columns values to lowercase for searching simplicity.

- One more operation we need to perform on the title column. All the title strings has one special character in the end, which will cause problem while searching for the movie in dataset. Hence removing the last character from all the elements of ‘movie_title’.

- Now we’ll sum up the text of all the features we’re going to use for measuring similarity in one column.

- Now after getting all the features summed up in one column in text form. We can make a similarity matrix. For making a similarity matrix, first we have to create count matrix of features.

- After importing the libraries, now let’s make count matrix of features and then similarity Score matrix. Similarity score matrix contains the cosine similarity of all the movies in the dataset. We can get the similarity score of two movies by there index in dataset.


- Now let’s name a movie user like. Convert it to small case, cause we converted all the title to smallcase. Then check if this movies exists in our dataset or not. This will Return True.

- Now, get the index of the movie in the dataset. Then fetch the row on the same index from the similarity score matrix, which has the similarity scores of all the movies to the movie user like.


- In the above step we also enumerated the row of similarity score, because for the most similar movies we have to sort this list in descending order, but we don’t want to lose the original index of similar movies, hence enumerating is important.
● Now, let’s sort the similarity score list on the basis of similarity score.

- Now we have the indexes of ten most similar movies to the movie user likes in the list. We just need to iterate through the list and store movie names on the indexes in a new list and print it.

- WOW ! We’ve got some good suggestions here. Now let’s define a function that will take the movie you like as input and will perform all the steps at once and will print the name of ten most similar movies to the movies you like.

As you can see here we are getting some really cool prediction form the function.
So now you’ve got the idea of how recommendation system works and how to build one.
I have also deploy HollyWood Movie Recommendation app on Heroku.
komal-movie-recommend-system.herokuapp.com